


Zach Seward recently gave this talk at SXSW. It was his first public presentation since starting his job as The New York Times’ first-ever editorial director of AI initiatives.
Hi, I’m Zach Seward, the editorial director of AI initiatives at The New York Times, where I’m building a newsroom team charged with prototyping potential uses of machine learning for the benefit of our journalists and our readers. Before that, I cofounded and spent more than a decade helping to run the business news startup Quartz, where we built a lot of experimental news products, some with AI.
I started at the Times not even three months ago, so don’t expect too much detail today about what we’re working on — I don’t even know yet. What I thought would be helpful, instead, is to survey the current state of AI-powered journalism, from the very bad to really good, and try to draw some lessons from those examples. I’m only speaking for myself today, but this certainly reflects how I’m thinking about the role AI could play in the Times newsroom and beyond.
We’re going to start today with the bad and the ugly, because I actually think there are important lessons to draw from those mistakes. But I’ll spend most of my time on really great, inspiring uses of artificial intelligence for journalism — both on uses of what you might call “traditional” machine-learning models, which are excellent at finding patterns in vast amounts of data, and also some excellent recent uses of transformer models, or generative AI, to better serve journalists and readers.
When AI journalism goes awry
CNET (Red Ventures)
So let’s start with those mistakes. Last January, CNET, the tech news site owned by Red Ventures, was revealed to be publishing financial advice — how much to invest in CDs, how to close your bank account, etc. — using what it called “automation technology,” although the bylines simply said, “Written by CNET Money Staff.”

The articles were riddled with errors emblematic of LLM “hallucinations” and had to be corrected. Some of the articles also plagiarized from other sources, another pitfall of writing copy whole-cloth with generative AI. Six months later, the same articles were thoroughly updated by humans whose names and photographs now appear in the byline area under the proud heading, “Our experts.”
This kind of advisory content has attracted some of the worst examples, I think, because it’s already seen by publishers as only quasi-journalism that really exists only to get you to buy a CD or open a new bank account through one of their affiliate links. It doesn’t often have the reader’s true interests at heart, and so who cares if the copy is sloppily written by a bot? This pattern repeats itself a lot:
Gizmodo and The Inventory (G/O Media)
Last year, G/O Media — and here I should disclose that I sold Quartz to G/O and spent one year in the company’s employ, though before any of these embarrassing mistakes. Well, G/O Media had a similar idea about generative AI, that it could do the job of journalism a whole lot more efficiently than journalists.
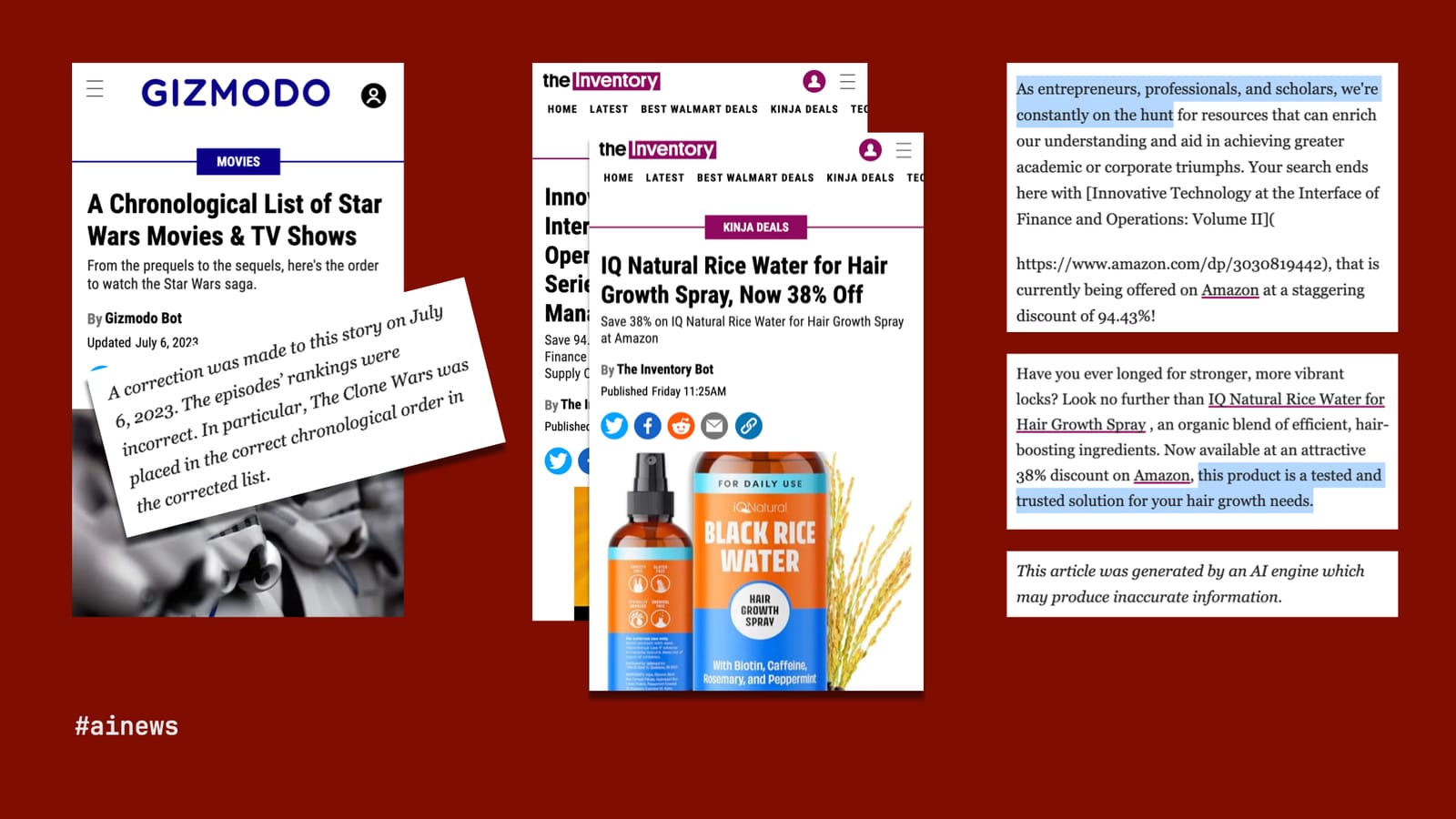
Naturally, G/O started with its biggest and best-known title, Gizmodo, and used an LLM to create a truly original piece of content: a chronological list of the Star Wars franchise. But “Gizmodo Bot,” as the byline read, was not the droid G/O was looking for. It had one job, and as Star Wars-obsessed fans across the internet were quick to point out, it failed, getting the chronology wrong.
Chastened by that high-profile mistake, G/O largely backed away from its AI experiments, but to this day, it continues to publish a raft of bot-written articles on its product-recommendation site, The Inventory, hawking such deals as 94.43% off a supply-chain management textbook and great savings on snake oil for your hair. More galling is some of the copy on these articles, in which “The Inventory Bot” refers to itself as an entrepreneur and suggests the products are “tested and trusted.” Only a brief line at the end of each article discloses—or, really, disclaims, “This article was generated by an AI engine, which may produce inaccurate information.” It may, but it’s all worth it for that rice-water affiliate revenue.
Sports Illustrated and The Street (Arena Group)
You get the idea. Arena Group, which licensed Sports Illustrated and owns The Street, was recently caught doing something similar with its AI-written reviews. The added spin here was that Drew, Sora, Domino, and Denise do not exist. Their photos were taken from a stock-imagery site. A lie on top of a lie on top of a lie.

AI journalism goes awry/works when it’s…
I’m not just trying to beat up on these companies, though they deserve it. I actually think we can draw some useful lessons. There are some common qualities across these bad examples: the copy is unchecked; the approach, as lazy as possible; the motivation, entirely selfish; the presentation, dishonest and/or opaque.


So how might we think about AI journalism that works? Well, it’s got to be vetted, in a rigorous way. The idea should be motivated by what’s best for readers. And, above all, the first principles of journalism must apply: truth and transparency.
Fortunately, we have plenty of such examples across a wide range of publishers using both traditional ML and generative AI. So let’s get into them.
Recognizing patterns with machine learning
Quartz
I’ll start with an example close to my heart, because we published it at Quartz in 2019. We were working with the International Consortium of Investigative Journalists, which had received an enormous cache of documents — too big for any human to go through page-by-page—from law firms that specialize in hiding wealth overseas. These particular documents came from the island tax haven of Mauritius.
Since reading all the documents, which included tax returns, financial data, and legal memoranda, wasn’t possible, my colleagues Jeremy Merrill and John Keefe built a tool that you might think of as “control-F on steroids.” ICIJ staff with expertise in tax avoidance identified passages of particular interest in a sample of the documents.
Jeremy then converted the plain text from all of the documents into vectors with arrays like you see on screen, using a model called doc2vec. This is the first step of how transformer models work, too. By transforming the Mauritius Leaks into multidimensional space, we could suddenly identify other documents that were similar to, though not exactly the same as, the original documents of interest. The model could identify patterns that no human would be able to spot.
It made the work of combing through the Mauritius Leaks not just more efficient, but actually just possible. We’re talking about 200,000 extremely technical documents. You can’t just read that page-by-page. You need the help of a machine.
Grist and The Texas Observer
The Texas Observer and Grist, a nonprofit newsroom dedicated to environmental coverage, did something similar with their investigation of abandoned oil wells in Texas and New Mexico, which numbered in the tens of thousands, so going to visit each one was out of the question. But they had data about the wells, both the roughly 6,000 wells already marked by the states as abandoned and tens of thousands of additional wells that seemed similar.

Machine learning is, at its core, just advanced math, and Clayton Aldern of Grist employed statistical modeling to compare conditions around the official list of abandoned wells with a much larger dataset of sites. They found at least 12,000 additional wells in Texas that were abandoned but off the books.
BuzzFeed News
So in those two examples, the journalists identified patterns in text and patterns in numerical data. This next example is very cool because Peter Aldhous, of the erstwhile BuzzFeed News, had a lot of publicly available flight data and a very keen insight: Planes usually fly from point A to point B, but when they circle an area over and over again, the plane is likely there to spy.
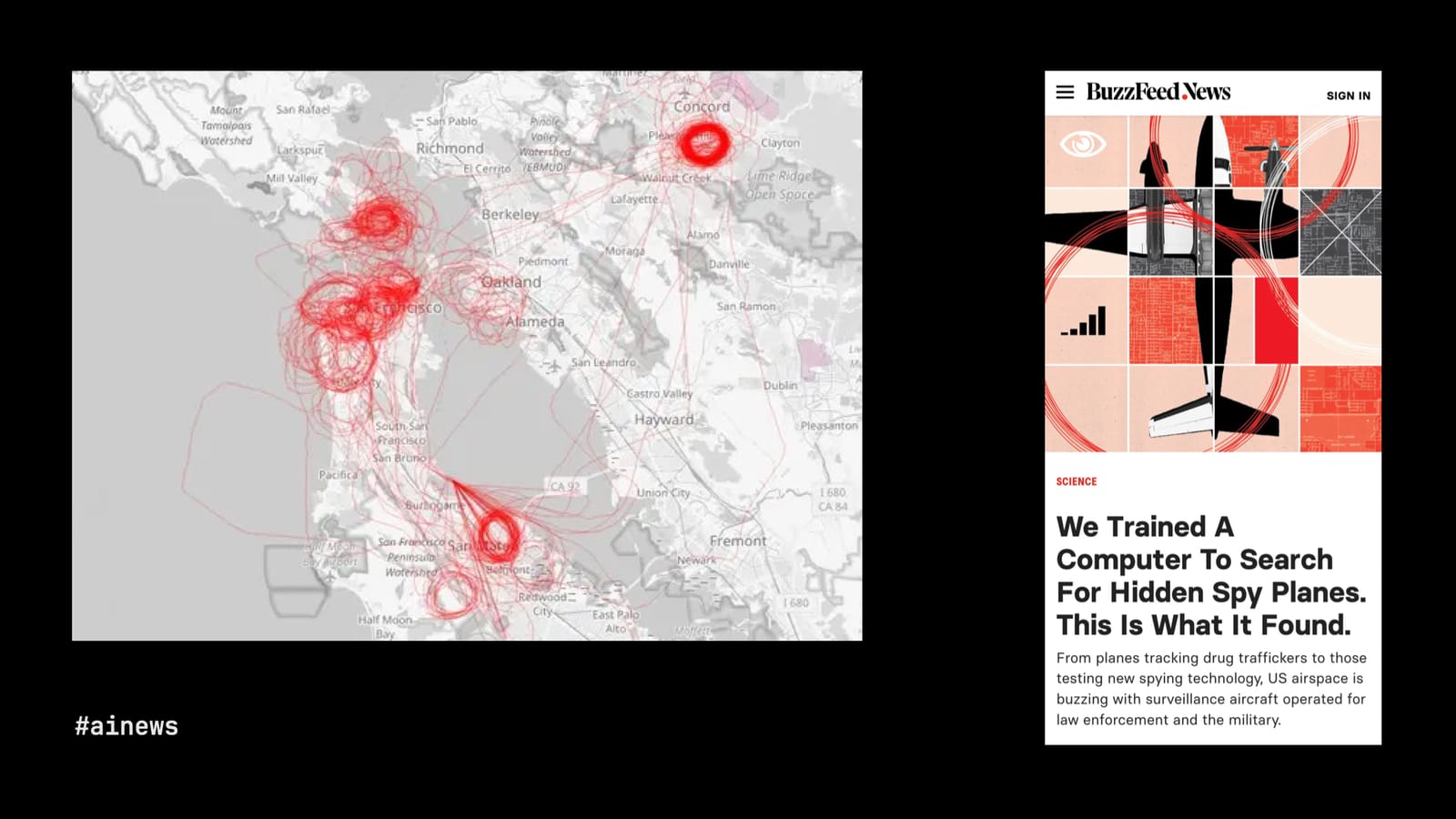
So Aldhous generated images of the flight patterns he collected and asked a machine-learning model trained on pattern recognition to find the circles. And, of course, not even spy planes fly in perfect loops, so the model’s ability to identify kinda-circles and almost-circles, to work within the rough edges of reality, was crucial. The investigation found loads of surveillance, by government and private aircraft, regularly occurring over major cities in the U.S.
The Wall Street Journal
Image recognition is a powerful tool for investigative journalism. The Wall Street Journal used it to great effect in a series of articles about quite how much lead cabling remains in the U.S., long after we realized the grave dangers of lead.

One aspect of the investigation, led by John Bebe-West, used Google StreetView images around schools in New Jersey. Now, to you and me, this just looks like an idyllic suburb on a partly cloudy day. But to a machine-learning model trained on what lead cabling looks like, it’s a public health crisis. The Journal found loads of lead cabling in public areas around the country, and went to a lot of those places to do actual tests for lead exposure, which in many cases found extremely high levels.
We can’t put a journalist on every street corner in America, but thanks to AI, we sort of can.
The New York Times
Likewise, we don’t have many journalists in space, at least not yet, but we do have voluminous imagery taken from the sky and available in close to real-time from startups that have launched satellites into low-orbit over the last decade.
My colleagues at The New York Times have used that satellite imagery to conduct some truly incredible investigations. For instance, after war broke out between Israel and Gaza, our Visual Investigations team wanted to account for Israel’s bombing campaign in southern Gaza, which was the supposed safe zone of the war. There was no official account of how many powerfully destructive bombs had been dropped there, but the bombs leave craters, and so:

The Times programmed an artificial-intelligence tool to analyze satellite imagery of South Gaza to search for bomb craters. The AI tool detected over 1,600 possible craters. We manually reviewed each one to weed out the false, like shadows, water towers, or bomb craters from a previous conflict. We measured the remaining craters to find ones that spanned roughly 40 feet across or more, which experts say are typically formed only by 2,000-pound bombs. Ultimately, we identified 208 of these craters in satellite imagery and drone footage, indicating 2,000-pound bombs posed a pervasive threat to civilians seeking safety across South Gaza.
That part of the work was led by Ishaan Jhaveri. It’s a great example of a story that simply could not have otherwise been told without machine learning paired with journalists and experts.
Machine learning can help recognize patterns in…
So we’ve seen how ML models are at their best, for journalism, when recognizing patterns the human eye alone can’t see. Patterns in text, data, images of data, photos on the ground, and photos taken from the sky.

Of course, a lot of this has been possible for many years. But there are some equally inspiring uses of the hottest new machine-learning technology, LLMs, or generative AI. If traditional machine learning is good at finding patterns in a mess of data, you might say that generative AI’s superpower is creating patterns. So let’s look at a few examples of that in action for news.
Creating sense with generative AI
The Marshall Project
The Marshall Project, a nonprofit newsroom covering the U.S. justice system, has been investigating what books are banned in state prisons and why. It maintains a database of the actual books, but also got its hands on the official policies that guide book banning in 30 state prison systems.
These are often long and esoteric documents, and The Marshall Project wanted to make the policies more accessible to interested readers. Its journalists went through each document to identify the parts that actually mattered, and then Andrew Rodriguez Calderón, using OpenAI’s GPT-4, employed a series of very specific prompts to generate useful, readable summaries of the policies. Those summaries were then reviewed again by journalists before publication.

If they had only needed to summarize one state policy, it might have been simpler to do the whole thing by hand. But by using an LLM, The Marshall Project could generate such summaries across all 30 states from which it obtained policies.
Watchdog reporting in the Philippines
Jaemark Tordecilla, a Filipino journalist and a 2024 Nieman Fellow, found similar success decoding bureaucratic documents with an LLM. He built a custom GPT trained to summarize audit reports of government agencies in the Philippines. These reports often turn up evidence of corruption, but they are very long and hard to read. Now, several Filipino journalists are making use of Jaemark’s tool to identify graft and find promising new lines of reporting.

Realtime
But I think most people, when they hear generative AI for journalism, imagine entirely automated news sites, like some of the bad examples we saw earlier. Well, here’s a fully automated site that I actually think does a good job providing value, while knowing its limitations, and using just the right amount of AI.
It’s called Realtime, a news site by Matthew Conlen and Harsha Panduranga, that charts regularly updated feeds of data from financial markets, sports, government records, prediction markets, public-opinion polls, etc. The data and charts are fully automated. The site tries to highlight charts that are showing interesting data, like an outlier, or particular strong growth or decline. So far, cool but basic math.

Where LLMs play a role is in providing context: the headlines and other brief copy that appear around the charts to help readers understand what they’re looking at. The air quality in New York today is good, subway ridership is still below pre-pandemic levels, but on the bright side, our fight against rats is showing progress.
These are really focused use cases for an LLM, and the fact that a bot wrote these reports is fully disclosed. It’s not a deep investigation into the war on rats, which I’d love to read, too, but it’s a certainly a helpful way to keep tabs on one’s city.
WITI Recommends
Here’s another website powered by an LLM, this time in the background. Why is this interesting? is a popular daily newsletter that’s been running for five years with lots of guest writers. Though it’s not exactly the point of the newsletter, each edition tends to reference one or more products that the writer likes. Which gave Noah Brier, one of co-founders of WITI, the idea of collecting all of those recommendations.

The problem, of course, was that the “recommendations” were buried in unstructured prose. Sometimes writers linked to products they hated or to things that aren’t for sale. How could Noah create a database of just the recommendations of just the products for sale across 1,500 editions of the newsletter? The answer was a carefully tailored prompt for GPT-4, which was able to extract and classify the product recommendations in a display-ready format.
People look at tools like ChatGPT and think their greatest trick is writing for you. But, in fact, the most powerful use case for LLMs is the opposite: creating structure out of unstructured prose.
Generative AI can make sense out of chaos by…
These last four examples, using generative AI, give us a sense of the technology’s greatest promise for journalism (and, I’d argue, lots of other fields). Faced with the chaotic, messy reality of everyday life, LLMs are useful tools for summarizing text, fetching information, understanding data, and creating structure.

But always, always with human oversight: guiding the summaries and then checking the results, teaching the bot to navigate an audit report, deciding when and when not to put the bot in control, and designing the rest of the software that powers the site. In all of these cases, it’s humans first and humans last, with a little bit of powerful, generative AI in the middle to make the difference.
Zach Seward is the editorial director of AI initiatives at The New York Times.